AI-based chatbot helps ITER users find information
After observing success and failure in other organizations, ITER has developed and deployed a first set of AI-based tools that deliver real value to a large user base.
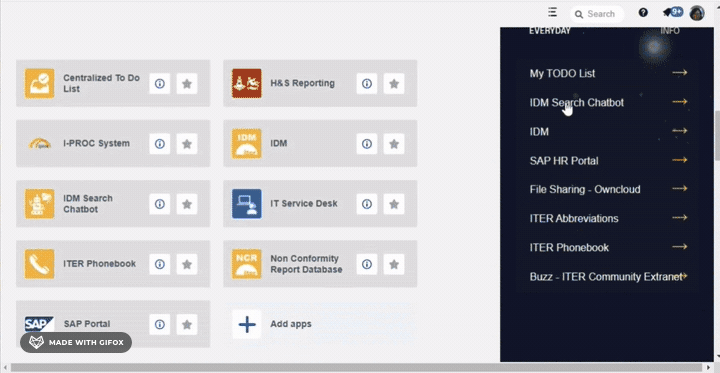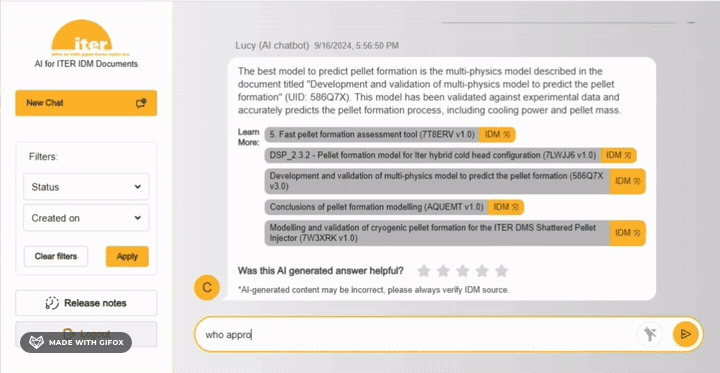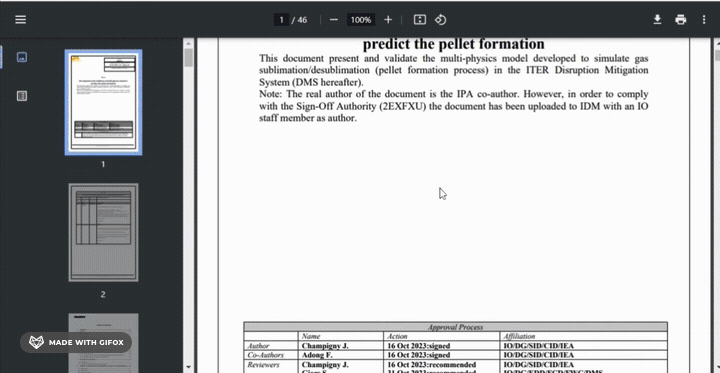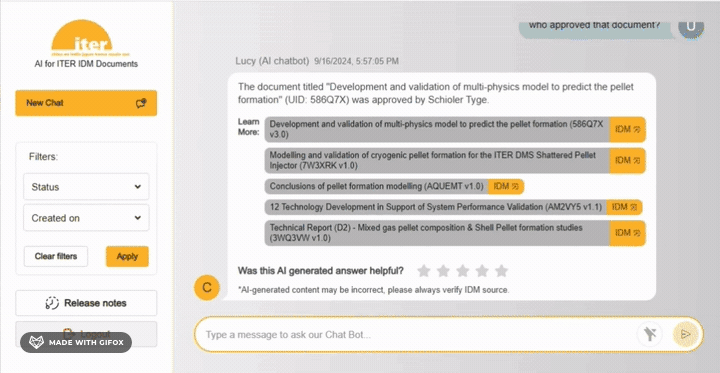
Near the end of 2023, the IT Project Tools Section within the Central Integration Division began to look at how it might apply artificial intelligence (AI) to improve ITER systems engineering processes. One use case that very quickly rose to the top of the list was facilitating information retrieval from the ITER Document Management (IDM) system which, some 20 years after it was first deployed, is widely used across the project.
While the IDM system has been generally well received, a recurring issue for users has been the difficulty in finding documents among approximately 1.5 million stored in the system. “We had made several attempts in the past to change the way we do searches on IDM, but that proved very challenging,” says Jean-Daniel Delaplagne, Section Leader for the IT Project Tools Section.
After a little brainstorming, Delaplagne’s team concluded that AI could solve the problem. They built a proof of concept (PoC) in Q1 2024—and improved it in an iterative fashion, through testing, until it was ready for the first production release in Q3 2024. In response to user feedback on the first version, a second major version was deployed in early January 2025, including a fundamental shift in architecture from standalone to multi-agent.
The new set of tools uses AI to summarize each document within the IDM system and the results are used to index all the information in a big vector database. The team developed an application that uses natural language processing to send queries to the vector database and return one or more responses using a popular technique called retrieval-augmented generation (RAG), which instead of just matching keywords like traditional search engines, allows users to ask questions and find semantically meaningful information.
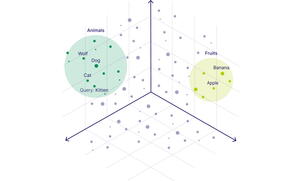
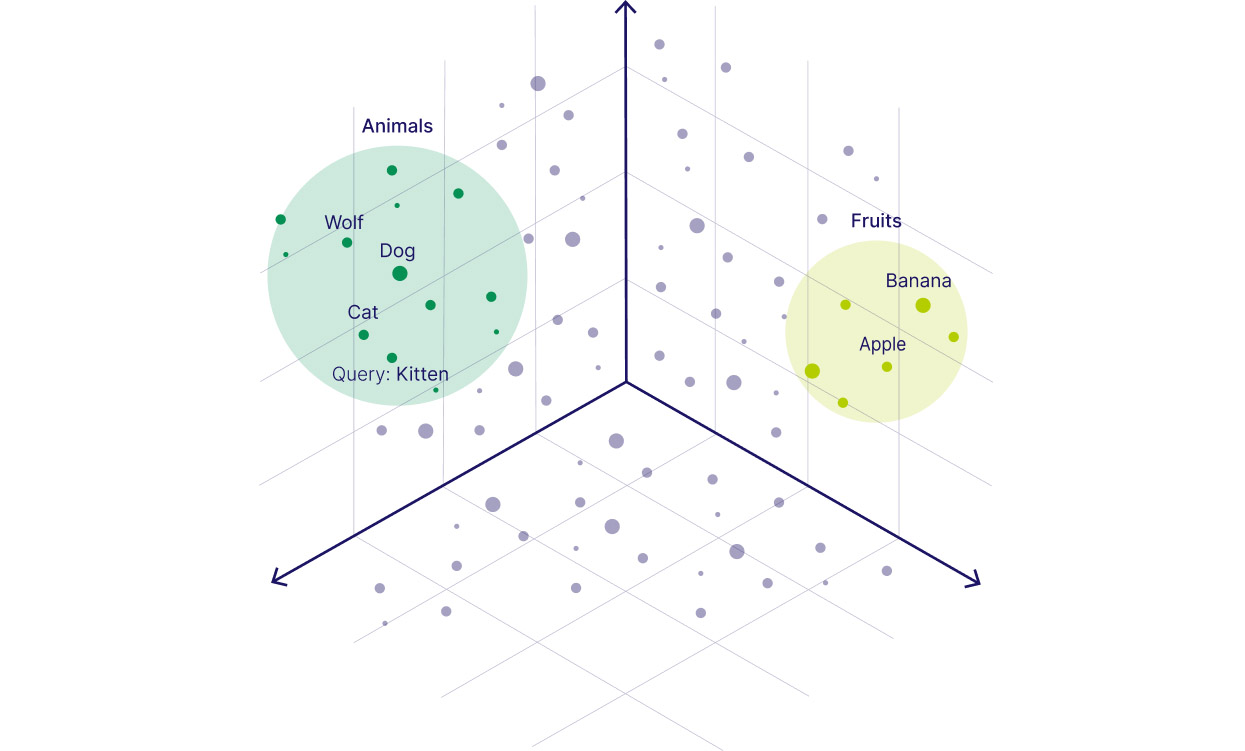
A good illustration of the way vector databases work is to imagine a document management system with information on cats, dogs, and birds. If a user asks a question about “animals” using a traditional keyword search, no matches are found. But with a vector database, the query would return all documents about cats, dogs, birds—and any other member of the semantic category “animal.”
“For the core AI backend capabilities, we decided to use the latest AI models from OpenAI,” says Junmin Yang, AI Project Lead in the IT Project Tools Section. “Users can ask questions in all the different languages supported by OpenAI—including Mandarin, Korean, Japanese, Russian and Hindi. But the answers are always in English to standardize the output and facilitate performance monitoring as English is the official language in the organization.”
The AI tool is accessible to about 120 partners—ITER and Domestic Agency employees, but also contractors with access to IDM. According to Yang, nearly a thousand people have used it so far, posting a total of 20,000 queries. The license fees paid to OpenAI average approximately €200 per month for that level of activity. Delaplagne says that since the first production release, users have sent in about 600 pieces of feedback, providing guidance to the team on how to tune and improve the RAG* model and other parts of the system.


Some of the comments after the first release were about the hundreds of acronyms used inside ITER. In response, the team created a specific agent inside the chatbot dedicated to answering questions on this topic, which was included in the January release. This solution was a fundamental shift to a more agent-based technical stack, which has implications beyond deciphering acryonyms. “Now we can create specific agents for different queries and get quicker results,” says Delaplagne. “We are now developing agents tailored to fetch information from sources outside of the IDM system to satisfy requests we’ve received from users to extend the search to other databases. For example, we recently added a new agent to answer questions about HOPs [hand over packages, which are sets of documents handed off from construction to commissioning].”
“We’re also planning to integrate the chatbot into applications people use at work on a daily basis,” says Yang. “This includes products in the Microsoft suite, like Teams and Microsoft Copilot.”
To allow users to make local choices about the large language models (LLMs) they use, IT plans to interface with other LLMs, such as Llama, DeepSeek and Mistral. According to Delaplagne, the new tools will also be made available to other organizations. “The IDM system is used in other fusion institutions, and we are already in contact with IPP [The Max Planck Institute for Plasma Physics] to deploy it there,” he explains.
The IT Project Tools Section is proud of having managed a project that went so quickly from a PoC to a production system used by a thousand people. “A lot of organizations have tried implementing chatbots, but not many have been able to go live and have it used by so many people on a day-to-day basis,” says Delaplagne. “It was a challenging project that we built with industrial partners like Microsoft, and we had good interns to do the coding to tailor the tools to our needs. It has been satisfying to deliver a tool that makes a real difference for IDM users.”
* RAG (retrieval-augmented generation) is a technique for enhancing the accuracy and reliability of generative AI models with information retrieved from external data sources.